Nowadays, many computers have multiple independent processing units. These are often underused, simply because writing parallel applications can be a daunting task. That is the case especially when the problem at hand is not easy to break apart into subproblems. However, there is a class of problems we often encounter in day to day work that consist of many independent units of data. Such tasks are trivial to parallelize. In this article, I consider three ways to parallelize such a task in a unix shell. I focus on bash and zsh because they are mostly compatible. They have their differences which complicate the solutions a bit. Still, compatible syntax can be found.
Let us consider a concrete, yet easily generalized, problem. Suppose we just downloaded a bunch of photographs from a camera, and discover all of them need to be flipped. Solving this is simple using the versatile ImageMagick package. Assuming we are in the right working directory:
for photo in *.jpg; do
mogrify -flip $photo
done
This will process photos one by one. But because they are independent, there is in principle no reason why this should be so. If our computer has multiple processors, we could process photos in parallel, one photo per processor. This would provide a significant speed boost.
Shells that are in interactive mode normally provide facilities for job control. We can put jobs in the background, so that they run in parallel, and leave it to the operating system to spread them across available processors.
for photo in *.jpg; do
mogrify -flip $photo &
done
Adding a simple ampersand does the trick. There is an obvious problem, however: this command starts to process all the images at once. If you have five of them, no problem. But running a hundred parallel image processing operations will bog down pretty much any computer. We therefore need a way to only launch a limited number of concurrent jobs, optimally exactly as many as there are processing cores.
Doing this, though simple in principle, can be a bit tricky. In the next sections, I provide three solutions in increasing order of complexity. Each has drawbacks and bugs, and I will explain those I know. Maintaining control while things run concurrently is not easy, and with the second and third solution, there are problems both known and, possibly, unknown. The main problem is that shells are meant mainly for interactive use, while we need solutions that work both in interactive and script mode. That means we have limited job control facilities, and sometimes have to deal with timing issues.
The ultimate goal is having a method to execute tasks in parallel that is simple to use from an interactive shell. Therefore, having a program distinct from the shell is not possible, because our task would have to be a separate program as well. This would rule out one-off commands, because implementing them as shell scripts would be a boring chore.
Shells have a builtin command called wait. It takes as arguments a list of PIDs, or Process IDs, to wait on. These processes need to be the shell's children. It can be run without arguments; then it waits on all the children.
It provides a simple way to limit the number of concurrent processes. Suppose we have a variable NR_CPUS which contains the number of processing cores we have available. We can then rewrite the photo flipping command like this:
count=0
for photo in *.jpg; do
mogrify -flip $photo &
let count+=1
[[ $((count%NR_CPUS)) -eq 0 ]] && wait
done
This will spawn jobs for as long as the count modulo the number of CPUs is nonzero. When count becomes the same as the number of CPUs, the modulo becomes zero, and the shell starts waiting for the child processes to complete. When they are all done, it spawns the next batch. This is quite simple, can be coded on-the-fly, and is robust. It is OK when all the tasks take about the same amount of time, i.e. when all the photos are the same size. If, however, the tasks don't take the same amount of time to complete, this solution is suboptimal. If we have, for example, four CPUs, it can happen that three of the jobs in a single batch are done very quickly, but the fourth one is much slower. The shell will wait for the fourth one, and only one CPU will be in use until it completes.
So we want to be able to start a new job as soon as any one of the earlier jobs is complete. If wait knows about all the child processes, we should be able to know about them as well, right? Well, yes and no. The interface to child processes is a bit clunky. We need to use job control, but it is only available in interactive shells by default. We can force it on using setopt -m in bash or set -m in zsh. However, even then, we can have problems because it's meant to be used in interactive mode.
If we have it enabled, we can write a function which I chose to call nrwait:
function nrwait() {
local nrwait_my_arg
if [[ -z $1 ]] ; then
nrwait_my_arg=2
else
nrwait_my_arg=$1
fi
while [[ $(jobs -p | wc -l) -ge $nrwait_my_arg ]] ; do
sleep 0.33;
done
}
This function takes an optional argument telling it how many concurrent jobs you want. It runs the shell builtin command jobs which prints a line for each running job, counts the number of lines using wc and compares it to the argument. If there are enough jobs, it sleeps. It does this check three times a second, which should be quite reasonable. If there are less than the wanted number of jobs running, it returns.
It's used like this:
for photo in *.jpg; do
mogrify -flip $photo &
nrwait $NR_CPUS
done
wait
Because nrwait returns when there are too few jobs, the loop continues spawning new ones until there are enough, at which point nrwait blocks and polls their status. Once you have this function in your profile or script, using it is even simpler than modular arithmetic. The explicit wait at the end of the loop makes sure that all the tasks are complete.
There are is a catch. Job control is very fragile when abused in this way. As a consequence, do not suspend the above loop, for example with the Ctrl+Z key combination. If you do, job control might cease to work, and the nrwait function will be unable to see any jobs. Therefore, the loop will start all the remaining jobs at once, possibly rendering the computer unusable until reboot.
The latter problem can be a showstopper in some circumstances. We need a more robust approach.
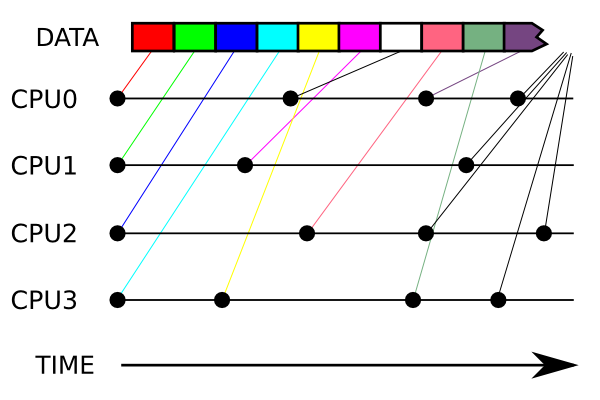
This image demonstrates what we wish to accomplish. We wish to process data using multiple CPUs, delivering it to them as they complete each task ("delivery" here means spawning a new process).
There is quite an elegant way to do this. Put all data (i.e. filenames in our photographic example) into an array. Have a variable that keeps the index of the current array element; when a new process is spawned, increment it. This should be done by a recursive function that first increments the index, spawns a new process, and when it completes, calls itself. Run as many of these functions as wou want in parallel, and that's it. Because they are all using the same, global, index, they are synchronised. We are, of course, assuming that incrementing the index is an atomic operation. If this is not so, the functions can desynchronise if they access it at the same time and there is trouble.
This doesn't have to worry us because this procedure cannot be implemented in a shell anyway. If you want to start several functions, you have to background them. When you background a shell function, it becomes a subshell, i.e. a separate process in its own right. It can see the values of the variables of the parent shell, but they are copies of those variables: modifying them has no effect on either the parent shell or the sister shells which contain the other instances of the function. Therefore, variables cannot be used as synchronisation entities for parallel execution of functions.
We obviously need to resort to interprocess communication. Pipes are out of the question for several reasons which are out of scope of this article. Temporary files are just as unwieldy, and so are sockets. The simplest way to communicate between processes are signals. These are intrinsic to job control as well: when a child process completes, the parent shell receives the SIGCHLD signal. But we are not going to work through job control. We will communicate process completion out of band using the SIGUSR1 signal, which by default has no use.
It should be said immediately that signals have their problems too. Therefore, this approach is not quite as good as it could be. However, the idea is sound, only the interprocess communication mechanism needs to be replaced. So let's take a look at signals anyway.
This solution is quite a bit more complicated than the previous two. The best way to explain it is by discussing the code, so here it is:
function mapp() {
if [[ -z $MAPP_NR_CPUS ]] ; then
local MAPP_NR_CPUS=$(grep "processor :" < /proc/cpuinfo | wc -l)
fi
local mapp_pid=$(exec bash -c 'echo $PPID')
local mapp_funname=$1
local -a mapp_params
mapp_params=("$@")
local mapp_nr_args=${#mapp_params[@]}
local mapp_current=0
function mapp_trap() {
echo "MAPP PROGRESS: $((mapp_current*100/mapp_nr_args))%" 1>&2
if [[ $mapp_current -lt $mapp_nr_args ]] ; then
let mapp_current+=1
(
$mapp_funname "${mapp_params[$mapp_current]}"
kill -USR1 $mapp_pid
) &
fi
}
trap mapp_trap SIGUSR1
while [[ $mapp_current -lt $mapp_nr_args ]]; do
wait
if [[ $mapp_current -lt $mapp_nr_args && $? -lt 127 ]] ; then
sleep 1
local mapp_tmp_count=$mapp_current
wait
if [[ $mapp_tmp_count -eq $mapp_current ]] ; then
echo " MAPP_FORCE" 1>&2
for i in $(seq 1 ${MAPP_NR_CPUS}) ; do
mapp_trap
done
fi
fi
done
for i in $(seq 1 ${MAPP_NR_CPUS}) ; do
wait
done
trap - SIGUSR1
unset -f mapp_trap
}
And here is how you use it:
function flipper() {
mogrify -flip $1
}
(mapp flipper *.jpg)
First, let's take a look at the usage example. The code that will be executed for every file is put into a shell function, here called flipper. This allows for comfortable interactive use, although as stated in the introduction, it forces us to implement this approach itself as a shell function so that it may have the same context. Although a function can cause problems because of traps it leaves behind, modified variables and such, we solve this by clearing traps after we're done and only using local variables.
Calling this function, which I named mapp, should be done in a subshell, which is done by putting the whole command between parentheses. It's not strictly necessary, but is a good thing to do for two reasons. First, when used in an interactive shell, the subshell will have job control disabled. This suppresses the messages a shell usually emits when a job is backgrounded and when it completes. These messages are usually welcome, but here they are just annoying clutter. Second, and more important, it allows us to use Ctrl+Z to suspend the whole command as a unit. Using a subshell affects the design of the mapp function, which is why I began the explanation with the usage example.
Let's analyse the mapp function. It begins by checking the MAPP_NR_CPUS environment variable, which is the analogue of the previously used NR_CPUS. If it is undefined, it reads the number of processors from the /proc/cpuinfo file, which is a nice trick, but you have to make sure your system supports this functionality (like linux does). Be careful: there is a tab in the grep pattern definition, not spaces!
Then the function proceeds to read the PID of the shell it's running in. We need to use a rather roundabout way to do it: spawning a new, "pure" shell (i.e. not a subshell) and asking it for the PID of the parent process through the $PPID variable. We cannot simply read the $$ special parameter, because we expect to run mapp in a subshell. While $$ normally contains the PID of the current shell, this does not apply to a subshell, where it contains the PID of the parent shell, which is the one we are either using interactively or is the script which utilises mapp. Because the mapp's parent shell is a subshell and we are going to define a signal trap in this subshell (see further), sending a signal to the real parent shell would kill it because it wouldn't have the trap.
Next, mapp reads the name of the function to "map" to the data (hence mapp's name) and put the rest of parameters into an array. We need to be careful to do this in a way compatible with both bash and zsh. Whereas in zsh, parameters are already an array, this is not so in bash. Also, in zsh, you need to pay attention to the KSH_ARRAYS shell option, as it alters indexing. Here, it is assumed to be set, therefore we use zero-based indexing. This makes it bash-compatible.
The mapp_trap function is defined inside the mapp function. I rather like this, epecially because it can be made undefined at the end of execution so that it doesn't pollute namespace, but not everyone thinks this is good style. It can, of course, be defined outside, as functions normally are. This function outputs the percentage of progress and checks whether there is still data left. If so, it runs the provided processing function, incrementing the index variable first. Following this, it uses the kill command to send the signal to parent shell. Because this function modifies the index variable mapp_current, it must not be backgrounded itself. Instead, it puts the processing function and the kill command into a subshell and backgrounds it.
After defining the trap function, we declare the trap itself. It is easy to see that by doing this, we have created the recursion described at the beginning of this section. Now, we could simply call mapp_trap as many times as we want, and the signals emitted by finished tasks would automatically launch new tasks.
However, there is a caveat. The recursion described earlier relies only on the atomicity of incrementing the index variable. The signal implementation has this atomicity problem as well, but because it uses a signal handler instead of a simple increment, it manifests itself differently. Unix signals are meant to be notifications of events. They only guarantee to tell you that something has happened, but not how many times it happened. In other words: when two or more signals arrive at the same time, they get merged into one. That means that if the process completes while a new one is just being launched, the one that has just finished will not be able to launch a new one. This race condition will happen.
The intent behind the while loop that follows the trap declaration is therefore obvious: to catch the race condition when it happens. Its side effect is also the launch of initial processes. To see how this works, we need to examine the wait command in more detail. When a signal arrives, the signal handler cannot be called immediately because, unless you're lucky, the shell is not running. The shell's purpose is starting programs and relinquishing control to them. So the signal handler can only be started when the current command completes and shell is back in control. When the handler completes, the shell continues where it left off.
The wait command is different, because it is a shell builtin, so the shell is in control. It's sole purpose is waiting for signals, in particular SIGCHLD. If another signal arrives and it has a handler, the handler is called. When it's finished, wait returns. The code that follows it can use it's return value, stored in the $? special parameter, to find out what happened. If wait returned because all child processes have finished or if there were no child processes to start with, it returns 0. If it returned because it was interrupted by a signal, it will return a value greater than 127.
So the while loop calls wait and checks what has happend. If wait keeps getting interrupted, everything is running fine. When it returns 0, we have to pay close attention. It might be that we're finished. However, if the value of the index variable says otherwise, there might be a problem. Most often, there is nothing wrong, it's just that the tasks have not properly started yet. To discover that, we wait for a moment (here hardcoded to be one second, but should be adjusted to the hardware) to let things settle, and call wait again. If the value of the index variable has changed, everything is fine and we continue as planned. If not, then there has been a severe race condition and it seems that all the signals have been ignored, thus all the branches are dead. This happens rarely, but it might. In that case, start a fresh set of processes.
mapp finishes with a for loop which simply calls wait a couple of times to ensure everything is finished. Once is not enough, because it might be that a process is still forking. After that, the trap is unset, and so is the definition of the mapp_trap function.
The first two solutions are rather simple and I have used them in practice, especially the first one since it's the oldest of the parallelisation tricks in my book, and since it works very well when the computer has few other tasks and the data is all the same. The second one scares me, since it can bring down a computer if you are not careful, which is the motivation behind developing the third method.
The third method satisfies the goal of being more stable than the second method, because the worst that can happen is that only a single branch is left running. I consider slightly better, but still very bad. It's been a while since I first wrote this text, and since then, I wrote prll, which builds on what I learned here. Most importantly, it uses System V Message Queues for interprocess communication, which means branches won't simply die out because the OS should ensure there are no race conditions. And yes, prll can be suspended, and does not need to be explicitly run in a subshell. I consider the ability to suspend the whole thing very important, because I use prll on a workstation which is used by several people at once. Working with large files causes heavy I/O, which can bring the machine to its knees. I consider giving other people a chance to start their application good manners.
I left the text mostly as-is, because it serves to document what I consider a severe limitation in a command-line interface. As everyone and their dog have multicore machines these days, a shell really should be capable of better job control. Until then, prll works well.